GPU architecture and CUDA programming
13 May 2018본 페이지에서는 GPU의 대표 모델별 architecture와 CUDA 프로그래밍
GPU에 대해서 이해를 위해선 먼저 엔비디아의 주요 제품군을 살펴볼 필요가 있다. 크게 그래픽카드 칩셋인 지포스(GeForce) 시리즈와 컴퓨터 그래픽스 개발를 위해 만들어진 그래픽 카드 칩셋 쿼드로(Quadro) 시리즈, 그리고 딥러닝과 같은 고성능 컴퓨팅용 카드인 테슬라(Tesla) 시리즈가 있다.

이 중 고성능 컴퓨팅 카드인 테슬라 시리즈 분류의 GPU 구조에 대해서 설명한다. 위의 그림과 같이 CPU 대비 GUP의 가장 큰 특징은 다수의 ALU로 구성되어 있다는 것인데, 이는 동시에 수많은 ㄴ벡터연산을 하드웨어 수행이 가능하다는것이다. 이러한 특징이 딥러닝 연산에 최적화되어 있는 것이다. 즉, CPU는 ALU 보다는 Controlblock과 cache가 많은 부분 구성되어 있었으나, ALU 연산에는 과도한 SPEC이기에 이러한 요소를 줄이고 ALU 연산에 최적화 시킨 것이다.
테슬라 시리즈에서 세대별 모델의 순서는 Fermi, kepler, Maxwell, Pascal로 아래의 두 그림과 같다.


이러한 하드웨어 구조에서 최적의 컴퓨팅 연산을 위해선 ALU 로직과 메모리 접근,fetcing 그리고 재분배 등과 같은 다양한 메모리 제어 방법이 필요하다 이에 따라 이러한 하드웨어와 최적으로 운용하기위한 SW가 필요하며 이러한 기술중 엔디비아가 개발한 대표적인 SW가 CUDA이다.


이러한 GPU 구조에서 CUDA 프로그래밍이 하는 역할은 다음 그림들과 같이 순차적으로 발생한다.
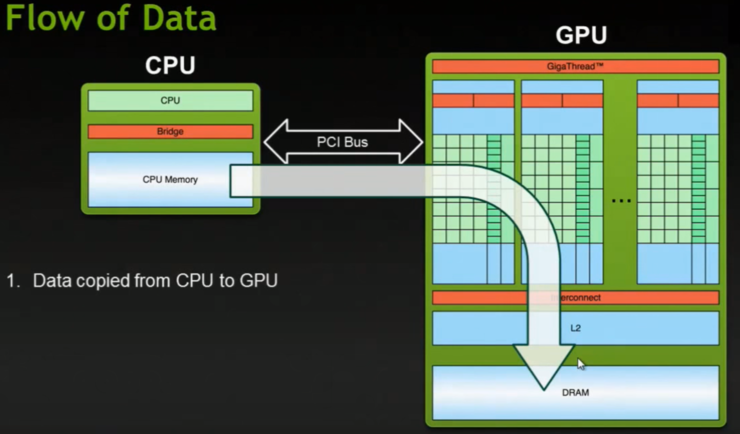
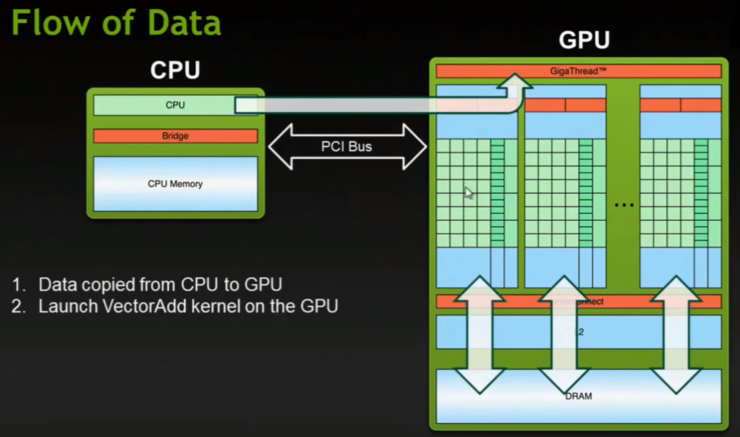
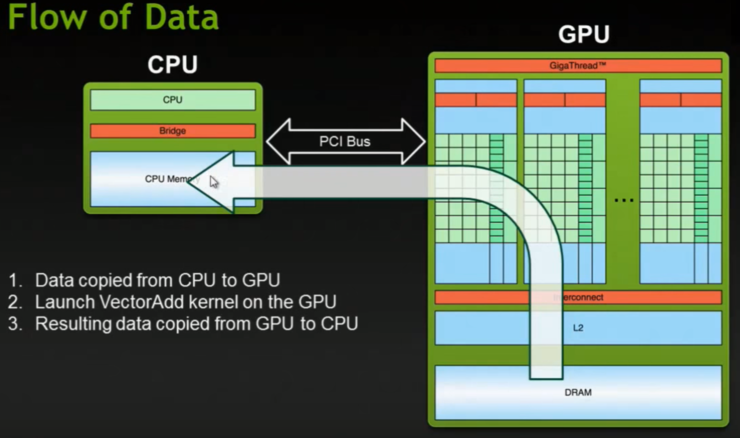
CUDNN은 딥러닝을 위해서 반복적으로 사용되는 컨볼루션, 폴링, signoid, Batchnorm(?)과 같은 기본적인 기능들을 정해진 알고리즘에 따라서 cuda 프로그래밍으로 사전에 구현해 놓은 라이브러리를 가리킨다. 예로 컨볼루션의 경우 gemm, fast gemm, FFT, Winograd 알고리즘이 대표적인 것이다.
아래의 그림은 gemm을 CUDA 프로그래밍으로 구현하는 기본 메카니즘을 보여준다.
